|
스크리밍데이타 주식회사는 2013년 서베이몽키 마케팅 에이전시로 출발해 엄격한 실사품질관리와 집요한 분석으로 제품과 서비스를 시장으로 이어주는 정보를 고객사에게 제공해오고 있습니다. 조사기획과 실사관리부터 최종 보고서까지 필요한 시장조사 서비스만 선별해 경제적인 비용으로 이용할 수 있으며, 마케팅 활동의 출발점이 되는 시장조사 역량을 내재화할 수 있는 지원을 받을 수 있습니다. |
ScremingData 개요

ScremingData 연혁 및 주요실적
- 2013년 6월 회사 설립
- 2013년 8월 SurveyMonkey 마케팅 에이전시
- 2013년 11월 옥션 트렌드 조사
- 2014년 2월 G마켓 브랜드 트래킹 조사
- 2014년 6월 삼성전자 해외 시장 조사 수행 시작
- 2014년 6월 현대모비스 고객 만족도 조사 수행 시작
- 2014년 8월 아모레퍼시픽 해외 시장 조사
- 2015년 5월 LG전자 해외 시장 조사 수행 시작
- 2015년 10월 (재)한국청년기업가정신재단 글로벌기업가정신지수 조사
- 2016년 1월 통계청 1호 사회적협동조합 리서치밸류플러스 참여
- 2016년 5월 영화산업실태조사
- 2016년 7월 삼성전자 미주지역 소비자 조사
- 2016년 7월 카페베네 광고효과조사
- 2016년 8월 경기지역 협동조합실태조사
- 2016년 10월 KCA 디지털 사이니지 수용조사
- 2017년 1월 인공지능스피커 콘셉트 조사
- 2017년 2월 삼성전자 가전제품 콘셉트 조사
- 2017년 3월 아파트 분양의향 조사
- 2017년 4월 구내식당 만족도 조사
- 2017년 5월 스마트폰 인식 및 사용성 조사
- 2017년 6월 삼성전자 가전제품 브랜드 해외 조사
- 2017년 6월 CJ E&M 프로그램 평가 조사 시작
- 2017년 6월 면도기 사용 행태 및 패키지 평가 조사
- 2017년 9월 구정 인식 조사
- 2017년 11월 안심귀가서비스앱 수용도 조사
- 2018년 2월 반려동물 사료 브랜드 모니터링 조사
- 2018년 3월 삼성전자 가전제품 해외 소비자 조사
- 2018년 4월 초고속인터넷 해외 소비자 조사
- 2018년 5월 성범죄 예방 조사
- 2018년 5월 기능성 화장품 콘셉트 수용도 조사
- 2018년 6월 HIRA 빅데이터 브리프 만족도 조사
- 2018년 7월 KCISA 실감형콘테츠 수요 조사
- 2018년 8월 등급분류제도 및 게임물이용실태조사
- 2018년 8월 반려동물 사료 KBB 조사
- 2018년 8월 사회적경제교육수요조사
- 2018년 8월 스마트폰 소비자 조사
- 2018년 8월 디지털 도어록 브랜드 점검 조사
- 2018년 10월 농촌개발시험연구사업 만족도 조사
- 2018년 10월 전력시설 및 한국전력공사에 대한 인식 조사
- 2018년 12월 가톨릭관동대학교 LINC+사업 수요조사
- 2019년 2월 한국만화영상진흥원 기관인식조사
- 2019년 4월 Luxury Buyer Insight Study
ScreamingData 주요 고객사

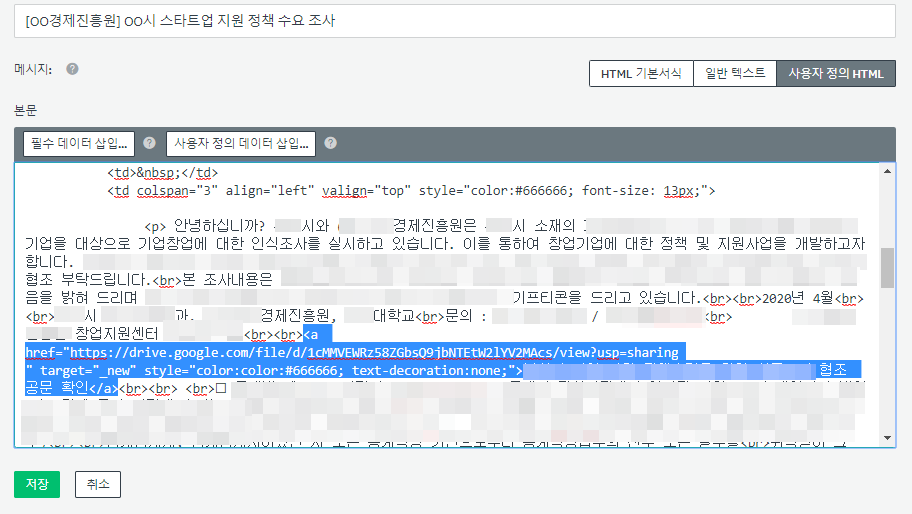
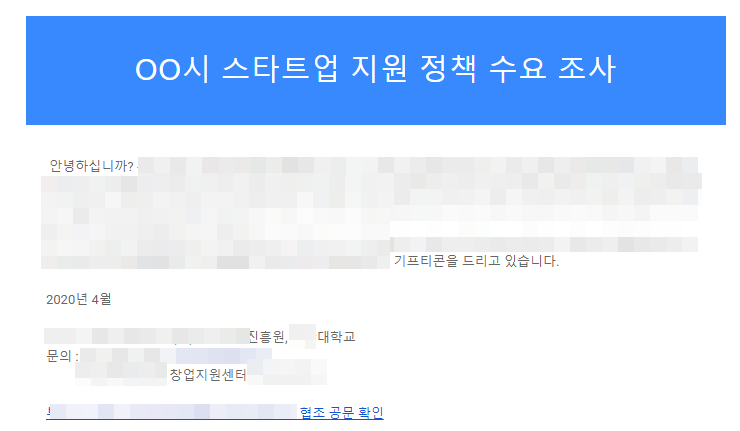
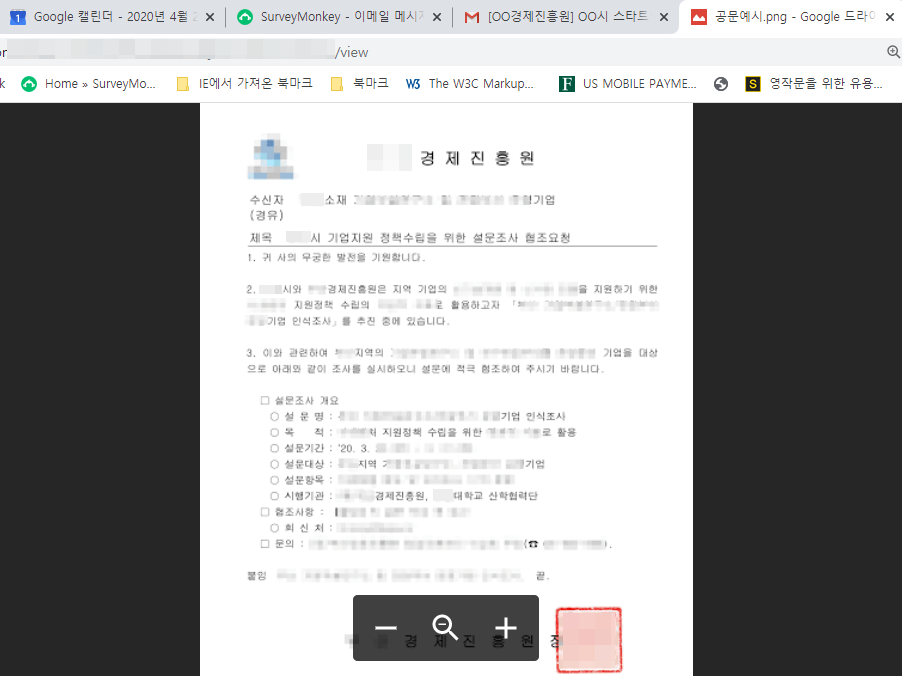
ScreamingData 맞춤형 서비스

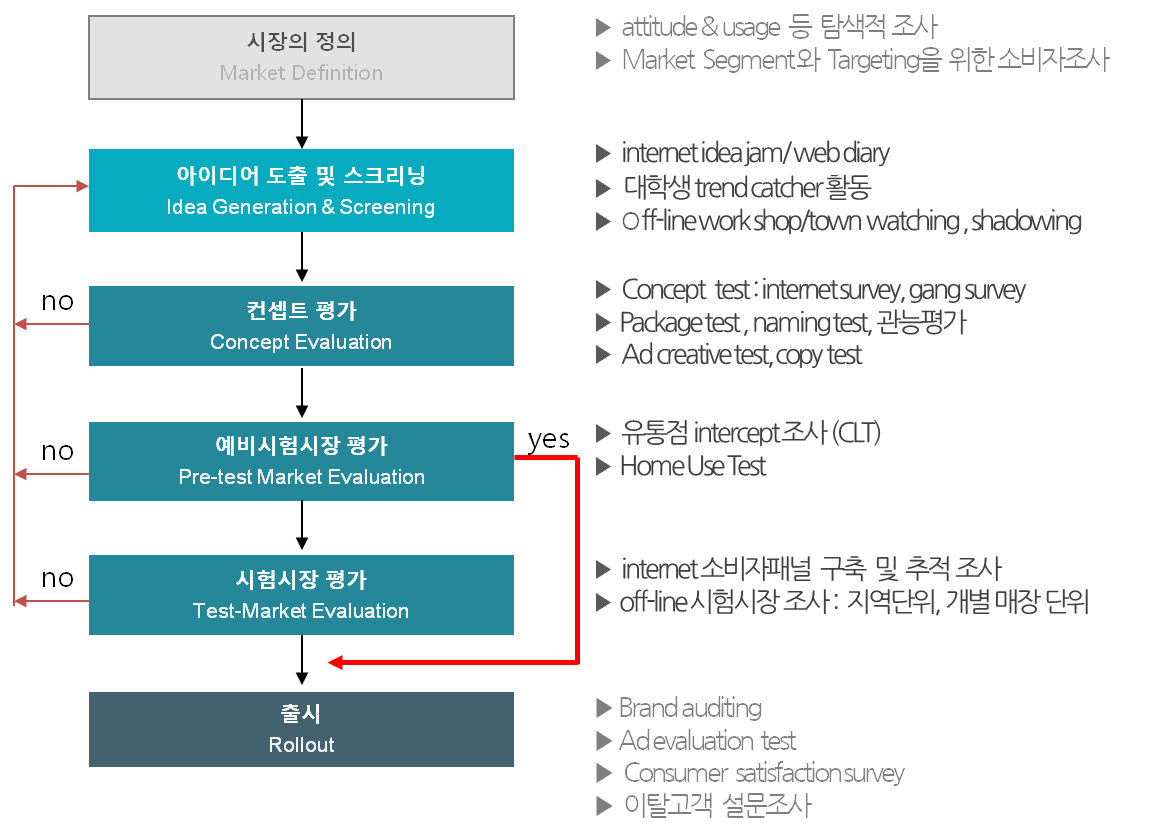
ScreamingData 분석사례 예시



'DataScreaming!' 카테고리의 다른 글
| 조사 보고서의 작성 및 활용 (0) | 2019.05.17 |
|---|---|
| 조사 품질 관리 (0) | 2019.05.09 |
| DataScream 제공 서비스 특·장점 (0) | 2019.05.08 |
| R을 이용한 텍스트 분석 - 네트워크 분석과 클러스터 분석 결과 (0) | 2018.01.22 |
| 영업권별 매출증진을 위한 고객만족도조사 결과의 활용 (0) | 2018.01.05 |